Содержание
Памятка для родителей. Как предотвратить синдром внезапной смерти младенца
Синдро́м внеза́пной де́тской сме́рти, СВДС — внезапная смерть от остановки дыхания внешне здорового человека или ребенка , при которой вскрытие не позволяет установить причину летального исхода.
Как предотвратить синдром внезапной смерти младенца (СВСМ)?
Можно существенно снизить риск СВСМ, следуя простым рекомендациям, разработанным педиатрическими сообществами мира. Соблюдение этих простых правил безопасного сна младенца позволить в значительной степени снизить не только риск СВСМ, но и смерть от внешних причин, таких как удушение, закупорка дыхательных путей, застревание головы ребенка между разными предметами.
Факторы социального риска СВМС:
· ночной сон в одной кровати с родителями, в том числе в состоянии опьянения,
· «пассивное» курение для ребенка — курение его матери, отца,
· отказ матери от исключительно грудного вскармливания в первые шесть месяцев жизни ребенка,
· самостоятельный перевод матери на кормление ребенка искусственной смесью
· многодетные матери,
· матери, воспитывающие детей без отцов,
· матери, ранее лишенные родительских прав на старших детей;
· юные матери в возрасте 16–20 лет,
· низкий уровень образования родителей,
· плохие жилищно-бытовые условия семьи, печное отопление,
· выход матери на работу и оставление грудного ребенка в ночное время на отцов, бабушек, старших детей;
· купание грудного ребенка в бане.
Факторы гендерного риска СВМС:
· мужской пол ребенка
Факторы психологического риска СВМС:
· ночной сон грудного ребенка в одной кровати с уставшей матерью,
· ребенок рожден от незапланированной беременности,
· нежеланный ребенок,
· недостаточное психологическое, эмоциональное внимание матери к ребенку,
· недостаточное внимание членов семьи к матери грудного ребенка, к матери, которая кормит грудью.
Факторы медицинского риска СВМС:
· преждевременные роды и рождение ребенка весом менее 2,9 кг;
· предшествующие аборты, выкидыши, мертворождения,
· болезни матери во время беременности, включая инфекции, передающиеся половым путем.
Реализация вышеперечисленных факторов риска в особой группе детей первого года жизни:
· ребенок родился больным, с врожденными заболеваниями,
· перенесенные ребенком грудного возраста операции,
· длительные периоды госпитализации в стационаре,
· излишняя или недостаточная прибавка в весе в первые месяцы жизни;
ПОМНИТЕ:
· 1. Кладите ребенка спать на спину! Внимание! Не используйте полотенца и различные подкладки, пытаясь уложить ребенка на спину, они могут стать причиной удушения ребенка.
Кладите ребенка спать на спину! Внимание! Не используйте полотенца и различные подкладки, пытаясь уложить ребенка на спину, они могут стать причиной удушения ребенка.
· 2. Внимательно отнеситесь к выбору места для сна ребенка! Заранее приготовьте для ребенка кроватку для сна. Матрас должен быть жестким. В кроватке не должно быть никаких игрушек, подушек, одеял, платков и других предметов, способных перекрыть дыхательные пути ребенка.
· 3. Совместный сон с ребенком на диване, в кресле несет в себе чрезвычайно высокий риск СВСМ или удушения ребенка!
· 4. Не используйте устройства, которые по заявлениям производителей направлены на предотвращения риска СВСМ их эффективность и безопасность не доказана!
5. Не оставляйте ребенка надолго спящим на машинном сидении, в коляске, детских качелях, надувных сиденьях, переносках для младенцев, слингах. Если ребенок уснул в одном из этих
Если ребенок уснул в одном из этих
· мест, как можно скорее перенесите его в колыбель или кроватку.
· 6. Спите в одной комнате, но не в одной кровати! Лучше, если первые полгода ребенок будет спать в одной с вами комнате. Не кладите ребенка спать с собой в постель – это увеличивает риск СВСМ даже у некурящих матерей. Укладывание младенца с собой в кровать так же может привести к удушению, перекрыванию дыхательных путей, придавливанию ребенка.
· 7. Не перегревайте своего ребенка.
· 8. Не курите! Практически все исследования определили, что курение во время беременности повышает риск СВСМ.
· 9. Не употребляйте алкоголь и запрещенные вещества во время беременности!
Не употребляйте алкоголь и запрещенные вещества во время беременности!
· Употребление алкоголя и запрещенных веществ — это факторы риска СВСМ. И, безусловно, эти факторы могут в значительной мере отразиться на здоровье вашего будущего ребенка.
· 10. Берегите ребенка от сигаретного дыма!
· Сохраняйте воздух вокруг ребенка в доме, машине и любом другом месте свободным от сигаретного дыма. Если кто-то из близких курит, убедитесь, что они делают это за пределами дома, квартиры. Если вы сами курите, то лучше всего бросить эту вредную привычку.
· 11. Вакцинируйте ребенка!
· Иммунопрофилактика инфекционных болезней путем вакцинации в соответствии с рекомендованным графиком может снизить риск СВСМ до 50%. Недоношенным детям и детям, перенесшим патологические состояния во время родов и в период новорожденности (первые 28 дней жизни) могут быть показаны дополнительные иммунопрофилактические мероприятия. Проконсультируйтесь по этому вопросу с врачами – неонатологами отделениям патологии новорожденных или участковым педиатром.
Проконсультируйтесь по этому вопросу с врачами – неонатологами отделениям патологии новорожденных или участковым педиатром.
· 12. Кормите грудью, если можете.
· Исключительно грудное вскармливание в течение 4-6 месяцев снижает этот риск СВСМ примерно на 70%.
Безопасность в автомобиле.
Если Вы планируете перевозить Вашего ребенка в автомобиле, обязательно используйте специальную люльку для перевозки младенцев – это защитит Вашего ребенка от травм в случае автомобильной аварии. Не думайте, что если Вы строго соблюдаете правила дорожного движения, то Вам ничего не угрожает, есть другие, менее опытные участники дорожного движения.
Безопасность при купании.
В последнее время участились случаи смерти детей от утопления во время купания. Никогда не оставляйте ребенка без присмотра во время купания.
Эти простые рекомендации помогут обеспечить безопасный сон вашего ребенка и сохранить ему жизнь!
Памятка для родителей по профилактике синдрома внезапной смерти младенцев
У Вас родился ребенок – это и радость, и счастье, это новая жизнь, полная надежд и открытий.
Но ребенок – это еще и ответственность. Ответственность за его жизнь, за его здоровье, за его счастье жить в семье, где будут любить, всегда защитят, всегда помогут. Чтобы счастье не померкло, чтобы внезапно мир не стал черно-белым, мы, взрослые, должны быть всегда рядом, готовые предотвратить любую беду.
А чтобы предотвратить беду, надо знать, откуда она может прийти. Синдром внезапной смерти младенцев (СВСМ) – опасный и пока мало изученный.
Исследования причин СВСМ ведутся уже не первый год учеными всего мира, и хотя среди них пока нет единого мнения о причинах возникновения этого синдрома, зато им удалось выделить «опасные» факторы и показать, что риск СВСМ может быть снижен.
Главные факторы риска:
- сон на животе;
- слишком мягкая поверхность кроватки;
- не рекомендуется подушка;
- курение матери в период беременности и кормления грудью, употребление алкоголя и психотропных веществ;
- недоношенность;
- перегревание (должно быть легкое одеяло до уровня плеч), излишне теплая одежда;
- переохлаждение;
- отсутствие родительского внимания;
- укачивание ребенка перед сном;
- тугое пеленание;
- новорожденные от 1 до 4 месяцев, мальчики чаще, чем девочки.

В первые 6 месяцев жизни дыхание и сердечный ритм младенцев еще очень нестабильны. Во время сна, все жизненные функции снижаются и иногда возникают физиологические паузы дыхания. Задача родителей – устранить любое препятствие для поступления воздуха: подушки, толстые одеяла. Ни в коем случае не кладите малыша спать с собой, у груди! Следите за тем, чтобы ребенок не перегревался. В этом случае мозг младенца начинает страдать и плохо контролирует центр дыхания.
При изучении этой проблемы установлено: самые опасные дни – суббота, воскресенье, праздничные дни, когда родители склоны отдохнуть и развлечься – потеря бдительности.
Самое опасное время с 4.00 до 6.00 утра.
Спать с грудным ребенком лучше в одной комнате, так легче контролировать его дыхание. Температура воздуха должна быть 18-20°С.
Кладите спать младенца только на спину. Во-первых, лежа на животе, малыш прижимает переднюю часть грудной клетки к матрасу, дыхательные пути при этом сужаются. Во-вторых, у спящего на животе малыша голова резко повернута в сторону, Это может ухудшить кровоснабжение мозга, как следствие — угнетение центра дыхания. Головной отдел кровати должен быть немного выше ножного.
Во-вторых, у спящего на животе малыша голова резко повернута в сторону, Это может ухудшить кровоснабжение мозга, как следствие — угнетение центра дыхания. Головной отдел кровати должен быть немного выше ножного.
Сон на боку менее опасен, но из этого положения ребенок легко переворачивается на живот.
Не курите! Ведь дети курят вмести с Вами, и вред от пассивного курения не меньше, чем от активного. Дети, курящих матерей, всегда(!) имеют проблемы с органами дыхания, а риск внезапной смерти повышается в 5 раз!
Избегайте воздействия на ребенка резких звуков, света, запахов табака, алкоголя, парфюмерии во время сна.
Будьте особенно бдительны в холодное время года с октября по март.
Грудное вскармливание является эффективным профилактическим мероприятием от СВСМ.
Не надо ждать, когда беда подойдет близко, ее можно и нужно пытаться предотвратить.
В первую очередь Вы являетесь ответственным за здоровье и жизнь вашего ребенка!
Фельдшер ГУЗ ГЦГДКП(для усиления профилактической работы среди здоровых детей) Гаврилова Н.
 В.
В. Оценка кредитного риска с помощью метода опорных векторов (SVM) | Джеки Лим | CodeX
SVM — это широко используемый контролируемый алгоритм машинного обучения как для задач классификации, так и для задач регрессии. Основными причинами его популярности являются его надежность (низкая дисперсия), способность обрабатывать многомерные данные (SVM применим в обстоятельствах, когда количество выборок меньше, чем количество предикторов, в отличие от линейной регрессии) и его способность обрабатывать данные. с нелинейным шаблоном данных.
Проще говоря, SVM состоит из четырех теоретических основ:
- Разделяющая гиперплоскость. В двухмерном пространстве это прямая линия, которая разделяет точки данных на две отдельные области.
- Максимальное поле, разделяющее гиперплоскость. Это эквивалентно нахождению линии, которая максимизирует расстояние между границей решения и ее ближайшими точками данных (векторами поддержки), также известной как запас.

- Мягкое поле. На самом деле, большинство наборов данных, с которыми мы сталкиваемся, не могут быть разделены разделяющей гиперплоскостью. В этом случае SVM позволяет некоторым экземплярам данных находиться не на той стороне поля или даже разделять гиперплоскость, вводя в свою формулировку такие параметры, как переменная резерва и стоимость C. Параметр C — это гиперпараметр, с которым мы можем работать для точной настройки модели SVM посредством k-кратной перекрестной проверки (CV).
- Функция ядра. SVM проецирует точки данных в многомерное пространство посредством отображения признаков. Это вычисление может быть легко решено с помощью функции ядра. Я настоятельно рекомендую этот пост Quora для более подробной информации о функциях ядра. Есть несколько доступных ядер, но я сосредоточусь на линейном ядре и ядре радиальной базисной функции (RBF).
В этом посте SVM применялся для различения плохой и хорошей кредитной истории. Согласно Investopedia, банковский кредит — это общая сумма денег, которую человек или компания может занять в банке./154/154.jpg) Данные были загружены из репозитория машинного обучения UCI. Согласно документу, связанному с данными, всего существует 20 предикторов и переменная отклика (хороший кредитный риск против плохого). Кроме того, автор также предлагает распределить стоимость неправильной классификации плохого риска как хорошего в пять раз выше, чем стоимость ошибочной классификации хорошего риска как плохого. Следовательно, стоимость ошибочной классификации будет использоваться в качестве целевой функции при поиске по сетке для нахождения оптимальной настройки гиперпараметров.
Данные были загружены из репозитория машинного обучения UCI. Согласно документу, связанному с данными, всего существует 20 предикторов и переменная отклика (хороший кредитный риск против плохого). Кроме того, автор также предлагает распределить стоимость неправильной классификации плохого риска как хорошего в пять раз выше, чем стоимость ошибочной классификации хорошего риска как плохого. Следовательно, стоимость ошибочной классификации будет использоваться в качестве целевой функции при поиске по сетке для нахождения оптимальной настройки гиперпараметров.
После небольшого введения в SVM и самих данных давайте приступим к кодированию.
Существует файл сценария R с именем «read_SouthGermanCredit.R», который поставляется вместе с загруженными данными. Запустите файл сценария в R, и полученный кадр данных «dat» — это обработанные данные, которые будут использоваться для анализа и моделирования. Я сохранил переменную «dat» как файл «.RData» в своем рабочем каталоге, поэтому мне нужно будет загружать файл RData только тогда, когда мне нужно.
Загрузить все необходимые пакеты.
library(rsample) # стратифицированная выборка
library(cdata) # обработка данных
library(ggplot2) # красивый график
library(GGally) # сгруппированная матрица точечной диаграммы
library(magrittr) # pipe
library(dplyr) # обработка данных
library(caret) # предобработка и преобразование данных
library(e1071) # svm
library(WVPlots) # график двойной плотности и кривая ROC
library(knitr) # tidy table
library(sigr) # вычисление AUC
Отображение внутреннего структура и статистическая сводка данных. Затем разделите данные с помощью стратифицированной выборки.
load("credit.RData")
str(dat)
summary(dat)
response='credit_risk'set.seed(10)
split=initial_split(dat,prop=0.8,strata = response)
train= training(split)
test=testing(split) Из вывода str() мы знаем, что существует 14 номинальных предикторов (без естественного ранжирования), 3 порядковых переменных (с естественным ранжированием) и 3 непрерывных предиктора.
Поскольку наши данные состоят как из категориальных предикторов, так и из непрерывных предикторов, нам нужно использовать различные графические выходные данные, чтобы визуализировать их распределения относительно переменной отклика.
Непрерывные предикторы
idx_con=c («длительность», «количество», «возраст»)
# Сгруппированный блок-график. Преобразование данных о поездах из широкого формата в длинный idx_con)ggplot(data=train_con_long, aes(x=credit_risk,y=values)) +
geom_boxplot(color="blue",fill="blue",alpha=0.2, вырез=TRUE,
outlier.color="red",outlier.fill = "red",outlier.size = 2) +
facet_wrap(~variables,ncol=3,scales = "free")
Приведенные выше диаграммы дают нам большое представление : плохой кредит вообще происходит от молодых кредиторов. Большая продолжительность, как правило, плохая кредитная история. Мы можем прийти к этим выводам, потому что выемки коробчатых диаграмм на панелях «возраст» и «длительность» не перекрываются, поэтому медиана двух групп (плохие и хорошие кредиты) значительно различается. Однако следует отметить наличие выбросов (обозначенных красными кружками). Таким образом, указанная выше зависимость не является окончательной.
Однако следует отметить наличие выбросов (обозначенных красными кружками). Таким образом, указанная выше зависимость не является окончательной.
Поскольку у нас есть несколько непрерывных предикторов, график корреляционной матрицы был построен, как показано ниже.
ggpairs(train_con,columns = 1:3, ggplot2::aes(color=credit_risk))
Переменные суммы и продолжительности имеют положительную корреляцию, что имеет смысл, поскольку для погашения кредита на большую сумму требуется больше времени. Классы не очень хорошо разделены, как показано на графиках плотности и графиках рассеяния.
Категориальные предикторы
Таблица непредвиденных обстоятельств — хороший способ получить лучшее представление о том, как категориальная переменная распределяется по меткам классов. В приведенном ниже фрагменте кода показано, как можно построить таблицу непредвиденных обстоятельств в R.
# таблица непредвиденных обстоятельств (количество)
таблица (поезд $ жилье, поезд $ кредит_риск)
Мы можем визуализировать таблицу непредвиденных обстоятельств, как показано ниже.
# Визуализация двух категориальных переменных: метод 1
ggplot(data=train) +
geom_count(aes(x=housing,y=credit_risk))# метод 2
train %>%
count(credit_history,credit_risk) %> %
ggplot(aes(x=credit_history,y=credit_risk)) +
geom_tile(aes(fill=n)) +
theme(axis.text.x = element_text(angle = 45,hjust=1))
Как определить связь между категориальными предикторами и переменной отклика? Критерий независимости хи-квадрат является надежной статистикой для проверки этой гипотезы.
train_cat=train[!(colnames(train) %in% idx_con)]t=c()Предикторы, не зависящие от переменной ответа: кредитный риск.
idx=c()
for (i in (1:(ncol(train_cat)-1))) {
t[i]=chisq.test(train_cat[i],train$credit_risk)$p.value
# u[i]=fisher.test(train[i],train$credit_risk)$p.value
, если (!is.list(tryCatch( { результат <- chisq.test(train[i],train$credit_risk) }
, предупреждение = функция (w) { печать («ИСТИНА») }))) {
idx = c (idx, i)
}
} idx_sig = which (t <= 0,05) idx_int =! (idx_sig % в % idx)
colnames(train_cat)[idx_sig[idx_int]]
Тест хи-квадрат может дать неточные результаты, если ожидаемая частота ячейки в таблице непредвиденных обстоятельств меньше 5.
Одним из недостатков SVM является то, что он не может обрабатывать категориальные признаки. Таким образом, категориальные предикторы должны быть предварительно обработаны или преобразованы в числовые значения. Горячее кодирование применялось к номинальным предикторам, тогда как кодирование по меткам применялось к порядковым предикторам. Непрерывные переменные стандартизированы до [0,1] посредством нормализации минимума и максимума. До этого момента мы должны знать об утечке данных. Чтобы предотвратить эту проблему, подготовка данных должна подходить только для обучающих данных. Фрагмент кода для приведенного выше преобразования для обучающих данных и данных удержания показан ниже.
# Выполнить одно горячее кодирование для категориальных (номинальных) предикторов.
библиотека(каре)
var_cat=c("статус","кредитная_история","цель","сбережения","продолжительность_работы",
"личный_статус_пол","другие_должники","имущество","другие_планы_рассрочки",
"жилье ","job","people_liable","телефон","иностранный_рабочий")train_cat=train[colnames(train) %in% var_cat]
dummy=dummyVars("~.",data=train_cat)
newdata=data .frame(predict(dummy,newdata=train_cat))# кодировка меток для порядковых переменных
# выбирает связанные переменные. (installment_rate)-1,
present_residence=as.numeric(present_residence)-1,
number_credits=as.numeric(number_credits)-1)# Мин-макс нормализация непрерывных предикторов
var_cont=c("amount","age" ,"длительность")
dat_cont=train[colnames(train) %in% var_cont]
process=preProcess(dat_cont,method = c("range"))
scaled_dat_cont=predict(process,dat_cont)# объединить все предикторы с переменной ответа по столбцам
train_new=cbind(newdata,train_cont,
scaled_dat_cont,credit_risk=train $credit_risk)# тестовые данные
# Горячее кодирование
test_cat=test[colnames(test) %in% var_cat]
newdata=data.frame(predict(dummy,newdata=test_cat))# Кодирование метки
test_cont=test [colnames(test) %in% var_ord]
test_cont=transform(test_cont,installment_rate=as.numeric(installment_rate)-1,
present_residence=as.numeric(present_residence)-1,
number_credits=as.numeric(number_credits)-1)
# Мин-макс нормализация
dat_cont=test[colnames(test) %in% var_cont]
scaled_dat_cont=predict( process,dat_cont)# объединить по столбцам
test_new=cbind(newdata,test_cont,
scaled_dat_cont,credit_risk=test$credit_risk)
Linear SVM
Параметр регуляризации C имеет решающее значение для определения производительности модели SVM. Высокое значение C подразумевает небольшой запас по обеим сторонам разделяющей гиперплоскости, таким образом, наказывается сделанная неправильная классификация, которая может привести к более сложной границе решения. Это потенциально может привести к проблеме переобучения.
Оптимальный параметр C можно найти методом поиска по сетке. Как упоминалось выше, стоимость неправильной классификации для обоих классов различна. Таким образом, целевой функцией поиска по сетке является стоимость неправильной классификации, а не настройка ошибки классификации по умолчанию.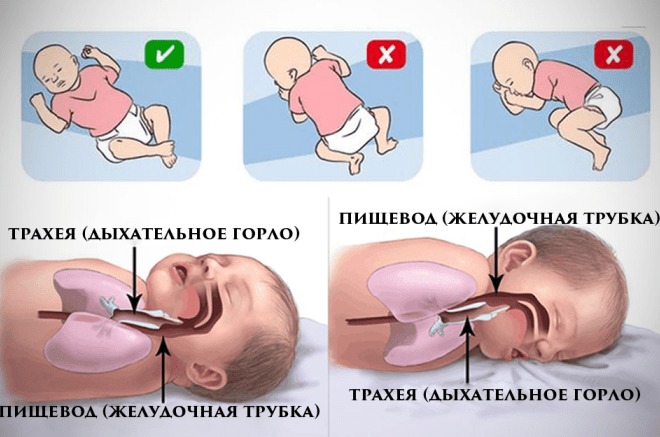 Меры точности могут ввести в заблуждение при решении проблем классификации, чувствительных к затратам. Веса (коэффициенты) линейного SVM (их знаки и абсолютные величины) полезны для изучения важности признаков и их вклада в окончательные результаты прогнозирования. Для получения более подробной информации, пожалуйста, обратитесь к этому сообщению об обмене ставками.
Меры точности могут ввести в заблуждение при решении проблем классификации, чувствительных к затратам. Веса (коэффициенты) линейного SVM (их знаки и абсолютные величины) полезны для изучения важности признаков и их вклада в окончательные результаты прогнозирования. Для получения более подробной информации, пожалуйста, обратитесь к этому сообщению об обмене ставками.
# Функция стоимости настройки гиперпараметровОптимальный C равен 16.
cost_matrix=matrix(c(0,1,5,0),ncol=2)
err=function(truth,pred){ pred)
tot_cost=sum(t*cost_matrix)
tot_cost
}range_exp=seq(-10,10,by=2)
set.seed(200) # для воспроизводимости
# SVM линейного ядра. Масштабирование не требуется, так как оно было выполнено заранее.
# Вес класса устанавливается обратно пропорциональным количеству выборок в
# каждом классе
svm_tune=tune(svm,credit_risk~.,data = train_new,kernel='linear', scale=FALSE, 9range_exp)),
tunecontrol = tune.control(cross=5,error.fun = err))
summary(svm_tune)
min_cost=svm_tune$performances$cost[what.min(svm_tune$performances$error)]# Визуализация
svm_tune$performances %>%
ggplot(aes(x=cost,y=error)) +
geom_line() +
scale_x_continuous(name = "cost, C",trans = "log2") +
ylab("стоимость ошибочной классификации ") +
geom_vline(xintercept = min_cost,
color="red",linetype=2)# Извлечь лучшую модель с точки зрения стоимости ошибочной классификации
svm_lin=svm_tune$best.model
coef_lin=data.frame(names=names(coef(svm_lin))[-1],coef=coef(svm_lin)[-1]) [order(-abs(coef_lin$coef))[1:10],]
rownames(coef_lin_10)=NULL
kable(coef_lin_10)# Визуализация оценок коэффициентов
ggplot(data=coef_lin_10,aes(x=names,y= coef)) +
geom_pointrange(aes(ymin=0,ymax=coef)) +
coord_flip() +theme_classic() + ylab("оценка коэффициентов")# первый столбец показывает выходные метки svm, второй столбец # соответствующие значения решения
data.frame(fitted=svm_lin$fitted[1:10],dv=svm_lin$decision.values[1:10])
В предыдущей таблице показано, что положительные значения решения относятся к плохой кредитной истории и наоборот.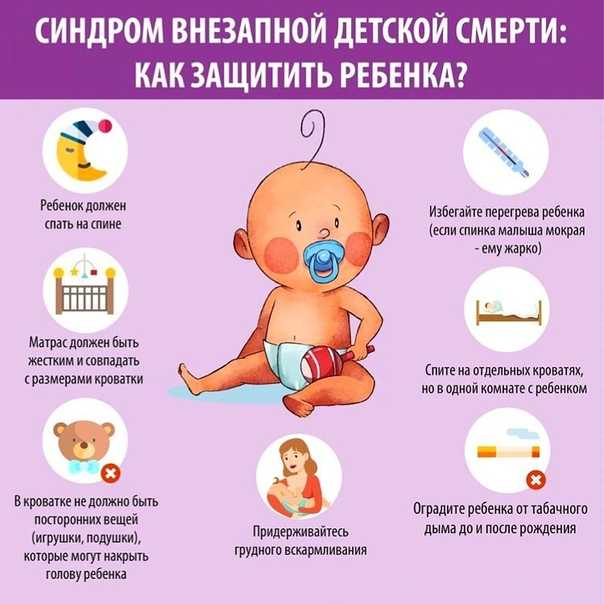 Таким образом, из приведенного выше графика мы можем понять, что стабильная заработная плата более 200 немецких марок (валюта Германии, следует отметить, что эти данные были собраны с 1973 по 1975 год) и хорошая кредитная история способствуют хорошему кредиту из-за их отрицательных признаков. С другой стороны, отсутствие текущего счета и большая продолжительность способствуют плохой кредитной истории.
Таким образом, из приведенного выше графика мы можем понять, что стабильная заработная плата более 200 немецких марок (валюта Германии, следует отметить, что эти данные были собраны с 1973 по 1975 год) и хорошая кредитная история способствуют хорошему кредиту из-за их отрицательных признаков. С другой стороны, отсутствие текущего счета и большая продолжительность способствуют плохой кредитной истории.
RBF SVM
Ядерная функция радиального базиса может быть выражена математически следующим образом:
Ядерная функция радиального базисаГамма, γ, как показано в приведенном выше уравнении, определяет, насколько далеко простирается влияние одного обучающего примера. Таким образом, C и γ — это гиперпараметры, которые необходимо оптимизировать. Сначала я начал с поиска по грубой сетке, а после нахождения «лучшей» области выполняется поиск по мелкой сетке, как это предлагается в этой статье. Код и соответствующий вывод можно найти в RPubs.
Оценка характеристик моделей SVM
Поскольку это проблема дихотомической классификации, можно построить график двойной плотности и кривую рабочих характеристик приемника (ROC). Показатели производительности, такие как точность, стоимость ошибочной классификации, точность, отзыв и мера f1, были рассчитаны для сравнения между линейным SVM и RBF SVM. Соответствующие коды и показатели производительности показаны ниже.
Показатели производительности, такие как точность, стоимость ошибочной классификации, точность, отзыв и мера f1, были рассчитаны для сравнения между линейным SVM и RBF SVM. Соответствующие коды и показатели производительности показаны ниже.
pred_svm_lin=predict(svm_lin,newdata=test_new,decision.values = TRUE)Производительность моделей SVM оценивается по тестовым данным.
pred_svm_rbf=predict(svm_rbf,newdata = test_new,decision.values = TRUE)
dat_plot=data.frame(outcome=test_new$credit_risk,dv_svm_linear=attr(pred_svm_lin",decision.values")[1:nrow(test_new)],
dv_svm_rbf=attr(pred_svm_rbf",decision.values")[1: nrow(test_new)])# график двойной плотности и парные ROC-кривые xintercept = 0, цвет = «красный», тип линии = 2) DoubleDensityPlot (dat_plot, xvar = «dv_svm_rbf», trueVar = «результат»,
title="Распределение оценок RBF svm (тестовые данные)") +
geom_vline(xintercept = 0, color="red", linetype=2)ROCPlotPair(dat_plot,xvar1="dv_svm_linear",xvar2 = "dv_svm_rbf",truthVar = «результат»,
trueTarget = «хорошо», title = «графики ROC для моделей SVM (тестовые данные)»)
2007/ST114/Untitled-3.gif)
Для этой проблемы отзыв (чувствительность) был бы очень важным показателем эффективности, на который следует обратить внимание, поскольку он говорит нам о способности классификатора идентифицировать потенциально плохой кредит для будущих невидимых данных. Как линейная модель, так и модель RBF SVM демонстрируют примерно одинаковые характеристики. Полные коды можно найти в каталоге RPubs и кредитных данных на Github.
Грёмпинг, У. (2019). Кредитные данные Южной Германии: исправление широко используемого набора данных. Отчет 4/2019, Отчеты по математике, физике и химии, кафедра II, Берлинский университет прикладных наук им. Бойта.
Kaggle: Кредитный риск (Модель: машины опорных векторов)
Более продвинутым инструментом для задач классификации, чем логит-модель, является машина опорных векторов (SVM) . SVM похожи на логистическую регрессию в том, что они оба пытаются найти «лучшую» линию (т. е. оптимальную гиперплоскость), которая разделяет два набора точек (т. е. классов).
е. классов).
Более конкретно, SVM находит гиперплоскость с максимальным запасом (т. е. с наибольшим разделением) в N-мерном пространстве (т. е. с количеством признаков), которая точно классифицирует точки данных. Гиперплоскость имеет размерность N-1, поэтому, если есть 2 (3) входных объекта, гиперплоскость является линией (двумерной плоскостью). «Опорные векторы» относятся к точкам данных, которые находятся близко к гиперплоскости и могут изменять ориентацию и положение гиперплоскости. На основе этих опорных векторов гиперплоскость может измениться.
SVM использует приемы ядра для преобразования необработанных наборов данных во входном пространстве в другое «богатое» пространство признаков, чтобы сложные задачи классификации можно было решать тем же «линейным» способом на основе нового альтернативного гиперпространства. Интуитивно мы можем видеть из вышеприведенного, что линия, разделяющая два класса точек, нелинейна, поскольку она «волнистая». Трюк ядра отображает необработанные данные в другое измерение, которое имеет четкую линейную границу , разделяющую между различными классами данных. SVM уникальны, поскольку для процесса сопоставления необработанных данных с новыми измерениями требуется только указанное пользователем ядро, а не указанная пользователем карта функций.
SVM уникальны, поскольку для процесса сопоставления необработанных данных с новыми измерениями требуется только указанное пользователем ядро, а не указанная пользователем карта функций.
SVM против логистической регрессии¶
1. Варианты использования¶
Как правило, линейные SVM и логистическая регрессия на практике имеют одинаковую производительность. SVM используются, когда ядро нелинейно, если ваш набор данных не является линейно разделимым, или ваша модель должна быть более устойчивой к выбросам. Таким образом, следует начать с логистической регрессии и перейти к нелинейной SVM с ядром радиальной базисной функции (RBF)
2. Функции потерь¶
SVM минимизируют функцию потери шарнира , которая максимизирует разницу (т. е. наибольшее расстояние) между двумя классами, а логит-функция минимизирует функцию логистических потерь , которая максимизирует вероятность апостериорной вероятности класса точек. Из рисунка, на котором сравниваются функции потерь на шарнирах и функций логистических потерь, мы видим два основных отличия, которые приводят к тому, что SVM является более надежной моделью по сравнению с логистической регрессией:
а.
 Точность¶
Точность¶Логит-функция не стремится к нулю по сравнению с функцией потери шарнира. Это приводит к несколько меньшей точности по сравнению с SVM.
б. Выбросы¶
Логит-функция расходится быстрее, чем функция потери шарнира. Это приводит к большей чувствительности к выбросам по сравнению с SVM.
3. Сложность и масштабируемость¶
SVM более сложны, поскольку могут поддерживать нелинейную классификацию. Отношение между временем подбора для SVM более чем квадратичное с количеством выборок. Следовательно, поскольку SVMS менее масштабируемы по сравнению с логистической регрессией, это объясняет, почему логит-модели по-прежнему широко используются в качестве эталонных моделей в приложениях машинного обучения. Обычно SVM следует использовать для наборов данных менее 10 000 выборок.
4. Вывод модели¶
SVM выдает двоичный результат (т. е. 1 или 0), тогда как логистическая регрессия выдает вероятностные значения [0,1]. Чтобы получить бинарный вывод в логистической регрессии, мы устанавливаем порог таким образом, чтобы вероятности выше (ниже) порога были равны 1 (0).
Чтобы получить бинарный вывод в логистической регрессии, мы устанавливаем порог таким образом, чтобы вероятности выше (ниже) порога были равны 1 (0).
Загрузка необходимых модулей Python¶
Загрузка обработанных фреймов данных¶
Чтобы узнать, как были получены приведенные ниже кадры данных, см. Сообщение на Kaggle: Credit Risk (Feature Engineering)
Выбор набора функций для обучения и тестирования модели¶
Назначьте наборы данных, которые вы хотите обучить и протестировать . Это связано с тем, что в рамках разработки функций вы часто будете создавать новые и разные наборы данных функций и хотели бы протестировать каждый из них, чтобы оценить, улучшает ли он производительность модели.
Поскольку импутатор подгоняется к обучающим данным и используется для преобразования обучающих и тестовых наборов данных, обучающие данные должны иметь то же количество функций, что и тестовый набор данных. Это означает, что
Это означает, что Столбец TARGET необходимо удалить из обучающего набора данных.
Для SVM мы используем выборку 5000 из исходного набора данных, так как подгонка SVM ко всем доступным данным (т. е. 48744 записи) потребовала бы слишком больших вычислительных ресурсов.
Мы видим, что наши выборки из 5000 являются довольно хорошим представлением исходного набора данных, учитывая, что число True (%) составляет 7% по сравнению с 8% в исходном наборе данных
Предварительная обработка набора функций¶
Мы подгоняем импьютер и масштабатор к обучающим данным и выполняем преобразования импьютера и масштабирования как для обучающего, так и для тестового набора данных.
Реализация модели (SVM)¶
Базовая модель¶
Мы выполняем базовое упражнение по дальнейшему разбиению нашего обучающего набора данных на тестовых и обучающих наборов данных. Наши наборы данных test составляют 20% от размера наших обучающих наборов данных
После того, как мы использовали обученную модель для прогнозирования целевой метки из X_test , мы вычисляем метрики Accuracy и ROC AUC Score. Полный спектр показателей производительности модели см. в документе Scikit-learn: Model Evaluation
Полный спектр показателей производительности модели см. в документе Scikit-learn: Model Evaluation
. Мы видим, что наша базовая модель SVM работает аналогично случайным предположениям, поскольку полученное значение AUC-ROC равно 0,5, что означает, что наша модель работает плохо. Сначала мы попробуем улучшить нашу модель с помощью перекрестной проверки, а затем настроим нашу модель с помощью гиперпараметров.
Мы используем 10-кратную перекрестную проверку, чтобы оценить, насколько хорошо работает наша модель.
Мы обнаружили, что в нашем упражнении по перекрестной проверке показатель ROC AUC выше — 0,61. Перекрестная проверка имеет эффект внутри выборки, поэтому, возможно, поэтому наша модель работает лучше, чем мы используем набор данных полностью вне выборки, такой как X_test для получения y_test .
Перекрестная проверка (послойная K-кратность)¶
Стратифицированная K-кратность отличается от обычной перекрестной проверки K-кратности тем, что стратификация приводит к реорганизации набора данных, чтобы гарантировать, что каждая кратность является хорошим представителем всего набора данных. Например, если у нас есть два класса (т. е. бинарные классификации) в нашем наборе данных, где
Например, если у нас есть два класса (т. е. бинарные классификации) в нашем наборе данных, где Target=1 составляет 30% и Target=0 составляет 70%, стратификация гарантирует, что в каждом сгибе каждый Target=1 и Target=0 будут точно представлены в контексте 30-70. Таким образом, стратификация является лучшей схемой, особенно когда наборы данных несбалансированы (т. е. доли разных классов очень разные, 99-1) и приводит к улучшению результатов с точки зрения систематической ошибки и дисперсии по сравнению с обычной перекрестной проверкой.
Мы видим, что результаты K-fold и стратифицированного K-fold аналогичны.
Настройка гиперпараметров¶
Большинство моделей машинного обучения имеют параметры, которые необходимо настроить для оптимизации производительности моделей. Поскольку SVM относительно менее сложен по сравнению с деревьями решений, случайным лесом и деревьями с градиентным усилением, мы рассмотрим относительно простой пример того, как подойти к настройке гиперпараметров.
Параметр степеней полинома¶
SVM могут выполнять нелинейную классификацию, и это выполняется с использованием ядра = поли или ядро = rbf . Хотя rbf является более популярным ядром на практике, poly со степенью 2 часто используется для обработки естественного языка. Ниже мы исследуем влияние использования различных степеней полинома на модель.
Из вышеприведенного мы видим, что степень полинома 2 дает наивысшую оценку roc_auc.
Гамма-параметр¶
Параметр гаммы является обратным значением стандартного отклонения ядра RBF (функция Гаусса) и используется в качестве меры подобия между двумя точками. Таким образом, малое (большое) значение гаммы приводит к функции Гаусса с большой (малой) дисперсией, что интуитивно означает, что две точки можно считать похожими, даже если они находятся далеко друг от друга (только если они расположены близко друг к другу).
Если гамма велика, то дисперсия мала, что означает, что опорный вектор не оказывает широкого влияния. С технической точки зрения, большая гамма приводит к моделям с высоким смещением и низкой дисперсией, и наоборот.
С технической точки зрения, большая гамма приводит к моделям с высоким смещением и низкой дисперсией, и наоборот.
Более высокое значение гаммы приводит к большему значению auc roc, поэтому мы должны использовать более высокое значение гаммы.
Параметр C¶
C — параметр для функции стоимости мягкой маржи, которая контролирует влияние каждого отдельного вектора поддержки. Выбор C является компромиссом между штрафом за ошибку и стабильностью. Интуитивно, C — это параметр, который указывает, насколько агрессивно вы хотите, чтобы модель избегала неправильной классификации каждого образца. Большие (маленькие) значения C приводят к тому, что оптимизатор ищет гиперплоскость с малым (большим) полем, если это приводит к более точной классификации (даже если это приводит к большей ошибочной классификации). Таким образом, большие (малые) значения C могут вызывать переобучение (недообучение). C необходимо выбрать, чтобы гарантировать, что обученную модель можно обобщить на точки данных вне выборки
Мы видим, что использование значения C выше 6 приводит к наивысшему показателю roc_auc.